کاربرد الگوریتم KNN چیست؟
Welcome!
This community is for professionals and enthusiasts of our products and services.
Share and discuss the best content and new marketing ideas, build your professional profile and become a better marketer together.
این سوال علامتگذاری شده است
2
پاسخها
322
نماها


الگوریتم k-Nearest Neighbor یا k نزدیک ترین همسایگی یکی از پایه ای ترین الگوریتم های یادگیری ماشین است. این الگوریتم یک الگوریتم مبتنی بر نمونه است. به این معنی که نمونه های های موجود در دیتاست آموزشی را به خاطر می سپارد و بر اساس شباهت بین این نمونه ها پیش بینی مربوط به نمونه های جدید و دیده نشده را انجام می دهد.
این الگوریتم همه نمونه ها را متناظر با نقاط در فضای n بعدی در نظر می گیرد. نزدیک ترین همسایگان یک نمونه با استفاده از فاصله اقلیدسی استاندارد تعیین می شوند. به طور دقیق تر، اگر نمونه x شامل مجموعه ویژگی های a1(x),a2(x),...,an(x) باشد، در نتیجه فاصله بین دو نمونه xi و xj به صورت زیر محاسبه می شود.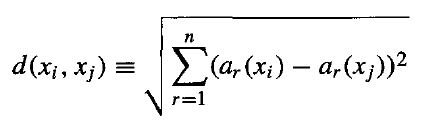
یکی از کاریرد های الگوریتم KNN در مسئله دسته بندی یا classification است. برای درک این مسئله، شکل زیر را در نظر بگیرید: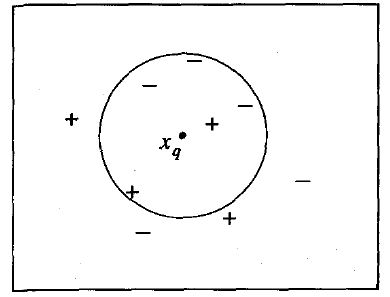
فرض کنید در شکل فوق می خواهیم نمونه xq را با استفاده از الگوریتم 5 نزدیکترین همسایگی یا 5-Nearest Neighbor دسته بندی کنیم (مثبت است یا منفی). برای اینکار ابتدا با استفاده از فاصله اقلیدسی، 5 نزدیک ترین نمونه آموزشی را مطابق شکل بدست می آوریم و بعد برچسب های این 5 نمونه بدست آمده بررسی می شوند. اگر اکثریت نمونه های موجود در این مجموعه 5 تایی مثبت باشند پس نمونه xq نیز مثبت دسته بندی می شود در غیر این صورت نمونه
xq منفی دسته بندی می شود. همانطور که در شکل مشاهده می شود تعداد نمونه های منفی بیشتر از نمونه های مثبت است، در نتیجه بر اساس الگوریتم 5NN نمونه xq منفی دسته بندی می شود.
به نظر من ابتدای پاسخ باید به صورت عمومی کاربرد این الگوریتم رو میگفتید بعد در مورد جزئیاتش صحبت میشد.
K-Nearest Neighbors یکی از ساده ترین الگوریتم های یادگیری ماشینی تحت نظارت است که برای طبقه بندی استفاده می شود. یک نقطه داده را بر اساس طبقه بندی همسایگان خود طبقه بندی می کند. تمام موارد موجود را ذخیره می کند و موارد جدید را بر اساس ویژگی های مشابه طبقه بندی می کند.
الگوریتم KNN زمانی مفید است که شما در حال انجام یک کار تشخیص الگو برای طبقه بندی اشیا بر اساس ویژگی های مختلف هستید.
فرض کنید مجموعه داده ای وجود دارد که حاوی اطلاعاتی در مورد گربه ها و سگ ها است. یک نقطه داده جدید وجود دارد و باید بررسی کنید که آیا آن نقطه داده نمونه یک گربه یا سگ است. برای این کار باید ویژگی های مختلف گربه ها و سگ ها را فهرست کنید
از بحث لذت می برید؟ فقط مطالعه نکنید، بپیوندید!
همین امروز یک حساب کاربری ایجاد کنید تا از ویژگی های انحصاری لذت ببرید و با جامعه عالی ما تعامل داشته باشید!
ثبت نام| نوشته های مرتبط | پاسخها | نماها | فعالیت | |
|---|---|---|---|---|
|
|
2
MMM yy |
383 | ||
|
|
1
MMM yy |
408 | ||
|
|
1
MMM yy |
342 | ||

|
1
MMM yy |
357 | ||
|
|
1
MMM yy |
395 |